This week’s Makeover Monday challenge (2020 w 27) was, at first, a breath of fresh air. A small data set! But in the course of designing a viz, and looking at others’, I learned a lot about the pitfalls of working with a small data set. I still don’t know that my presentation of the data is perfect (for whatever that’s worth), but below are a few of the "gotchas” that I tried to avoid.
We’re missing some context
This data set is from 2014, so pretty out of date now. The article that it came from was written in 2018, and the report on which the article was based on was written in 2016. A lot may have changed since 2016! To combat this effect, I did make sure to note the date of the source data in the footer. That, I believe is good enough for this challenge, but if this were an official publication, I’d want to validate that those findings were still relevant before distributing it.
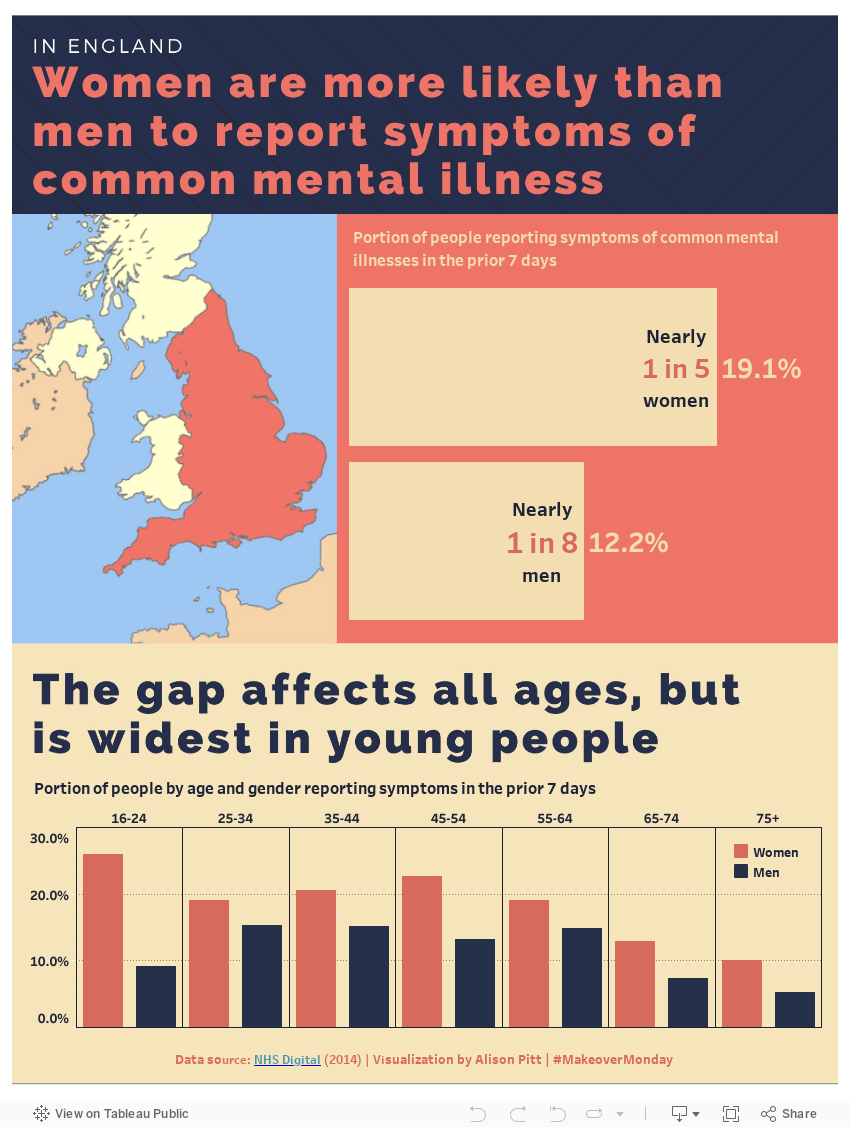
This data set is also highly localized, in a way that is easily misconstrued. According to the original study, “39 per cent of adults aged 16-74 with conditions such as anxiety or depression, surveyed in England, were accessing mental health treatment, in 2014.” One thing to note here: England is NOT the same as the United Kingdom. England is just one of four distinct countries that make up the United Kingdom and as anyone who has lived there will tell you, England has its own culture and history and should not be conflated with the UK as a whole. When you include the other three countries in a study, you’re getting a whole different data set, which is not something people outside the UK might be aware of.
Side note: Tableau’s built-in maps are terrible for delineating the countries of the UK. They don’t appear to be able to handle the country-in-a-country issue and jump straight from UK boundaries to county boundaries (Lincolnshire, London, Wiltshire, etc.)
Description of the issue is vague
The source article for this challenge is vague in the issue it’s trying to address, and doesn’t clearly state the limitations of what it’s presenting. In the text of the source article, you can ascertain that this is data pertaining to self-reported symptoms of common mental illness, so it excludes any physician-diagnosed symptoms or more severe mental illness. Here are two bad takes on this data:
This data set can be taken as a proxy for all mental health occurrences in the UK - this take is BAD because it fails to account for the self-reporting aspect, and it fails to discern between “common” and “serious” symptoms. Not to mention the UK/England conflation that I mentioned earlier!
This data set means that mental health issues disproportionately affect women - another BAD take, because it fails to address that men might simply report symptoms less readily.
All we can really tell from this specific data is - literally - the rate at which women and men self-report some symptoms of mental illness. Any further inference is pretty irresponsible. Personally, I took the approach of using exactly the same wording in my viz as was presented in the original article (“self-reported”, “common mental illness”).
The subject matter is sensitive
People who are experiencing or have experienced mental health issues can be triggered by discussions of said mental health issues. There is also a stigma around people who experience mental health issues that we should be mindful of as well. Autumn (@aabattani) on Twitter did a good job self-monitoring this, after advice from Simon Beaumont (@SimonBeaumont04): “Simon brought up am important point about this week's #MakeoverMonday data. I updated my wording to be mindful of the stigma around mental illness. We should be as conscious about what the data doesn't tell us as we are with what goes into the viz. Thank you @SimonBeaumont04”
Simon brought up am important point about this week's #MakeoverMonday data. I updated my wording to be mindful of the stigma around mental illness. We should be as conscious about what the data doesn't tell us as we are with what goes into the viz. Thank you @SimonBeaumont04 https://t.co/4RqXG4Bsn7 pic.twitter.com/Yj0XKg50uw
— autumn🍂 (@aabattani) July 6, 2020
Takeaways
This week’s challenge looked simple at first, and the more I looked at it, the more interesting it got. Not because of the data, but because of the challenges it presented to me as an analyst, trying to make sure that I didn’t editorialize the data, and presented it as accurately and factually as possible, without changing the meaning.
This week’s exercise also made me think a lot about data lineage (which has been the subject of a few recent data.world talks, too), and how difficult it might be to accurately explain figures like this to an audience that is unlikely to spend time researching the background of the data. Lots to think about here!
About the viz
I used Canva to design the overall viz, then used it as a dashboard background and dropped in the two bar charts. I don’t recall doing anything particularly special with the charts, but I did spend a ridiculous amount of time fiddling with their appearances and fonts!

The four-color palette for this week’s viz
A final note
I wish I’d been able to glean an actionable insight out of this one…but in the end I didn’t feel there was enough information here, so I opted for a straight visualization of the data. I think this viz would work best as part of a larger study, with more context and information.